nuScenes Dataset Tutorial¶
nuScenes Dataset Overview¶
The full nuScenes dataset contains 1,000 scenes (20 seconds duration each) and includes approximately 1.4M camera images, 390k LiDAR sweeps, 1.4M RADAR sweeps, and 1.4M object bounding boxes across 40k keyframes. For detailed annotation instructions, refer to the official documentation.
The dataset provides comprehensive data from an autonomous vehicle’s complete sensor suite:
6 Cameras (Basler acA1600-60gc): 12Hz capture frequency, 1600×900 ROI, surround view with one rear-facing camera
1 LiDAR (Velodyne HDL32E): 20Hz capture frequency, 32 beams, 1080 (±10) points per ring, usable returns up to 70 meters, ±2 cm accuracy, up to ~1.39 million points per second
5 RADAR (Continental ARS 408-21): 13Hz capture frequency, 77GHz, up to 250m distance, independently measures distance and velocity using Frequency Modulated Continuous Wave
GPS and IMU (Advanced Navigation Spatial): Position accuracy of 20mm
Coordinate System and Synchronization¶
Extrinsic coordinates are expressed relative to the ego frame (the midpoint of the rear vehicle axle). The cameras operate at 12Hz while the LiDAR runs at 20Hz. The 12 camera exposures are distributed as evenly as possible across the 20 LiDAR scans, meaning not all LiDAR scans have corresponding camera frames. All annotations and metadata (including calibration, maps, vehicle coordinates, etc.) are stored in a relational database.
nuScenes-lidarseg Extension¶
The nuScenes-lidarseg extension provides semantic segmentation labels for each LiDAR point from keyframes, with 32 possible semantic categories. This extension contains 1.4 billion annotated points across 40,000 point clouds and 1,000 scenes (850 scenes for training/validation, 150 scenes for testing).
Dataset Setup and Installation¶
Download and Extract Dataset¶
Download nuScenes data from https://www.nuscenes.org/nuscenes
Extract the mini sample data, which creates four folders: “maps”, “samples”, “sweeps”, and “v1.0-mini”
Install Development Kit¶
tar zxvf .\v1.0-mini.tgz
pip install nuscenes-devkit
Basic Usage Example¶
Create a tutorial notebook at mydetector3d/datasets/nuscenes/nuscenes_tutorial.ipynb:
from nuscenes.nuscenes import NuScenes
nusc = NuScenes(version='v1.0-mini', dataroot='/data/cmpe249-fa22/nuScenes/nuScenesv1.0-mini', verbose=True)
nusc.scene[0] # Each scene is a 20s sequence with 'token', 'name', 'first_sample_token', 'last_sample_token'
Full Dataset Extraction (HPC Environment)¶
Extract the complete nuScenes dataset:
(mycondapy39) [010796032@coe-hpc2 nuScenes]$ tar zxvf v1.0-trainval01_blobs.tgz
$ tar zxvf v1.0-trainval02_blobs.tgz
$ tar zxvf v1.0-trainval03_blobs.tgz
$ tar zxvf v1.0-trainval04_blobs.tgz
$ tar zxvf v1.0-trainval05_blobs.tgz
$ tar zxvf v1.0-trainval06_blobs.tgz
$ tar zxvf v1.0-trainval07_blobs.tgz
$ tar zxvf v1.0-trainval08_blobs.tgz
$ tar zxvf v1.0-trainval09_blobs.tgz
$ tar zxvf v1.0-trainval10_blobs.tgz
(mycondapy39) [010796032@cs001 nuScenes]$ tar zxvf v1.0-trainval_meta.tgz
(mycondapy39) [010796032@coe-hpc2 nuScenes]$ ls samples/
CAM_BACK CAM_BACK_RIGHT CAM_FRONT_LEFT LIDAR_TOP RADAR_BACK_RIGHT RADAR_FRONT_LEFT
CAM_BACK_LEFT CAM_FRONT CAM_FRONT_RIGHT RADAR_BACK_LEFT RADAR_FRONT RADAR_FRONT_RIGHT
(mycondapy39) [010796032@coe-hpc2 nuScenes]$ ls sweeps
CAM_BACK CAM_BACK_RIGHT CAM_FRONT_LEFT LIDAR_TOP RADAR_BACK_RIGHT RADAR_FRONT_LEFT
CAM_BACK_LEFT CAM_FRONT CAM_FRONT_RIGHT RADAR_BACK_LEFT RADAR_FRONT RADAR_FRONT_RIGHT
(mycondapy39) [010796032@cs001 nuScenes]$ ls maps/
36092f0b03a857c6a3403e25b4b7aab3.png 53992ee3023e5494b90c316c183be829.png
37819e65e09e5547b8a3ceaefba56bb2.png 93406b464a165eaba6d9de76ca09f5da.png
(mycondapy39) [010796032@cs001 nuScenes]$ ls v1.0-trainval
attribute.json category.json instance.json map.json sample_data.json scene.json visibility.json
calibrated_sensor.json ego_pose.json log.json sample_annotation.json sample.json sensor.json
sweeps/RADAR_FRONT/n008-2018-08-01-15-52-19-0400__RADAR_FRONT__1533153432872720.pcd
.v1.0-trainval02_blobs.txt
Organize Dataset Structure¶
Organize all folders within the “v1.0-trainval” directory:
nuScenes/v1.0-trainval$ ls
attribute.json category.json instance.json map.json sample_data.json scene.json visibility.json
calibrated_sensor.json ego_pose.json log.json sample_annotation.json sample.json sensor.json
nuScenes/v1.0-trainval$ mkdir v1.0-trainval
nuScenes/v1.0-trainval$ mv *.json ./v1.0-trainval/
nuScenes/v1.0-trainval$ mv ../maps .
nuScenes/v1.0-trainval$ mv ../samples/ .
nuScenes/v1.0-trainval$ mv ../sweeps/ .
nuScenes/v1.0-trainval$ ls
maps samples sweeps v1.0-trainval
Dataset Preprocessing¶
Generate Info Files¶
Run create_nuscenes_infos in /home/010796032/3DObject/3DDepth/mydetector3d/datasets/nuscenes/nuscenes_dataset.py to generate info.pkl files:
total scene num: 850
exist scene num: 850
v1.0-trainval: train scene(700), val scene(150)
nuscenes_utils.fill_trainval_infos # For all samples, train_nusc_infos.append(info)
info = {
'lidar_path': Path(ref_lidar_path).relative_to(data_path).__str__(),
'cam_front_path': Path(ref_cam_path).relative_to(data_path).__str__(),
'cam_intrinsic': ref_cam_intrinsic,
'token': sample['token'],
'sweeps': [],
'ref_from_car': ref_from_car,
'car_from_global': car_from_global,
'timestamp': ref_time,
}
camera_types = [
"CAM_FRONT",
"CAM_FRONT_RIGHT",
"CAM_FRONT_LEFT",
"CAM_BACK",
"CAM_BACK_LEFT",
"CAM_BACK_RIGHT",
]
for cam in camera_types:
info["cams"].update({cam: cam_info})
info['sweeps'] = sweeps
gt_boxes = np.concatenate([locs, dims, rots, velocity[:, :2]], axis=1) # dims is dxdydz (lwh)
info['gt_boxes'] = gt_boxes[mask, :]
info['gt_boxes_velocity'] = velocity[mask, :]
info['gt_names'] = np.array([map_name_from_general_to_detection[name] for name in names])[mask]
info['gt_boxes_token'] = tokens[mask]
info['num_lidar_pts'] = num_lidar_pts[mask]
info['num_radar_pts'] = num_radar_pts[mask]
train_nusc_infos.append(info)
train sample: 28130, val sample: 6019
pickle.dump(train_nusc_infos, f)
pickle.dump(val_nusc_infos, f)
(mycondapy39) [010796032@cs001 nuScenes]$ ls v1.0-trainval
maps nuscenes_infos_10sweeps_train.pkl nuscenes_infos_10sweeps_val.pkl samples sweeps v1.0-trainval
Generate Ground Truth Database¶
Run “create_groundtruth” in “nuscenes_dataset.py” to generate the ground truth database:
nuscenes_dataset = NuScenesDataset
include_nuscenes_data # Load nuscenes_infos_10sweeps_train.pkl
self.infos.extend(nuscenes_infos)
Total samples for NuScenes dataset: 28130
nuscenes_dataset.create_groundtruth_database
database_save_path=gt_database_{max_sweeps}sweeps_withvelo
db_info_save_path=f'nuscenes_dbinfos_{max_sweeps}sweeps_withvelo.pkl'
for each info
points (259765, 5) last column is time
gt_boxes (10, 9)
gt_names (10,)
save relative gt points as 0_traffic_cone_0.bin (sample_idx, gt_names[i], i)
db_info = {'name': gt_names[i], 'path': db_path, 'image_idx': sample_idx, 'gt_idx': i,
'box3d_lidar': gt_boxes[i], 'num_points_in_gt': gt_points.shape[0]}
save db_info to all_db_infos
Database Statistics¶
3DDepth/mydetector3d/datasets/nuscenes/nuscenes_dataset.py
======
Loading NuScenes tables for version v1.0-trainval...
23 category,
8 attribute,
4 visibility,
64386 instance,
12 sensor,
10200 calibrated_sensor,
2631083 ego_pose,
68 log,
850 scene,
34149 sample,
2631083 sample_data,
1166187 sample_annotation,
4 map,
Done loading in 25.048 seconds.
2023-05-21 08:46:41,467 INFO Total samples for NuScenes dataset: 28130
Database traffic_cone: 62964
Database truck: 65262
Database car: 339949
Database pedestrian: 161928
Database ignore: 26297
Database construction_vehicle: 11050
Database barrier: 107507
Database motorcycle: 8846
Database bicycle: 8185
Database bus: 12286
Database trailer: 19202
Database Info Structure¶
Each database info entry contains:
gt_points.tofile(f) # Saved
db_info = {'name': gt_names[i], 'path': db_path, 'image_idx': sample_idx, 'gt_idx': i,
'box3d_lidar': gt_boxes[i], 'num_points_in_gt': gt_points.shape[0]}
Dataset Structure Summary¶
After extraction, the dataset contains:
samples folder: Sensor data for keyframes (annotated images)
sweeps folder: Sensor data for intermediate frames (unannotated images)
.v1.0-trainvalxx_blobs.txt files (01-10): JSON tables containing all metadata and annotations
Dataset Testing and Validation¶
Dataset Loading Test¶
Based on the code in mydetector3d/datasets/nuscenes/nuscenes_dataset.py, run the dataset test:
(mycondapy39) [010796032@cs002 3DDepth]$ python mydetector3d/datasets/nuscenes/nuscenes_dataset.py --func="test_dataset"
2023-06-24 08:40:58,003 INFO Loading NuScenes dataset
2023-06-24 08:41:01,748 INFO Total samples for NuScenes dataset: 28130
2023-06-24 08:41:02,045 INFO Total samples after balanced resampling: 123580
Dataset infos len: 123580
Info keys:
lidar_path
cam_front_path
cam_intrinsic
token
sweeps
ref_from_car
car_from_global
timestamp
cams
gt_boxes
gt_boxes_velocity
gt_names
gt_boxes_token
num_lidar_pts
num_radar_pts
Model Training¶
Training Configuration¶
Training was conducted on HPC2 cs001 using GPU2 and GPU3 with two different model configurations:
Model 1: BEVFusion
Configuration:
mydetector3d/tools/cfgs/nuscenes_models/bevfusion.yamlTrained model:
/data/cmpe249-fa22/Mymodels/nuscenes_models/bevfusion/0522/ckpt/checkpoint_epoch_56.pth
Model 2: CBGS PP Multihead
Configuration:
mydetector3d/tools/cfgs/nuscenes_models/cbgs_pp_multihead.yamlTrained model:
/data/cmpe249-fa22/Mymodels/nuscenes_models/cbgs_pp_multihead/0522/ckpt/checkpoint_epoch_128.pth
Model Evaluation Results¶
Initial Evaluation (June 2023)¶
(mycondapy39) [010796032@cs002 3DDepth]$ python mydetector3d/tools/myevaluatev2.py
2023-06-24 01:53:41,721 INFO Loading NuScenes dataset
2023-06-24 01:53:42,790 INFO Total samples for NuScenes dataset: 6019
recall_roi_0.3: 0.000000
recall_rcnn_0.3: 0.661513
recall_roi_0.5: 0.000000
recall_rcnn_0.5: 0.429482
recall_roi_0.7: 0.000000
recall_rcnn_0.7: 0.182539
Average predicted number of objects(6019 samples): 126.934
Finished detection: {'recall/roi_0.3': 0.0, 'recall/rcnn_0.3': 0.6615132459191865, 'recall/roi_0.5': 0.0, 'recall/rcnn_0.5': 0.4294822049772545, 'recall/roi_0.7': 0.0, 'recall/rcnn_0.7': 0.18253947016323255, 'infer_time': 171.54541744346238, 'total_pred_objects': 764018, 'total_annos': 6019}
(mycondapy39) [010796032@cs002 3DDepth]$ python mydetector3d/tools/myevaluatev2_nuscenes.py
Saving metrics to: /data/cmpe249-fa22/Mymodels/eval/nuscenes_models_cbgs_pp_multihead_0624/txtresults
mAP: 0.4103
mATE: 0.3363
mASE: 0.2597
mAOE: 1.3475
mAVE: 0.3272
mAAE: 0.1999
NDS: 0.4929
Eval time: 71.6s
Per-class results:
Object Class AP ATE ASE AOE AVE AAE
car 0.780 0.201 0.158 1.648 0.294 0.211
truck 0.456 0.374 0.196 1.607 0.262 0.242
bus 0.545 0.378 0.187 1.573 0.569 0.238
trailer 0.289 0.541 0.197 1.494 0.271 0.152
construction_vehicle 0.093 0.771 0.444 1.528 0.129 0.362
pedestrian 0.701 0.169 0.281 1.358 0.260 0.088
motorcycle 0.305 0.225 0.247 1.355 0.584 0.273
bicycle 0.033 0.190 0.275 1.492 0.251 0.033
traffic_cone 0.451 0.184 0.326 nan nan nan
barrier 0.450 0.329 0.286 0.073 nan nan
Result is saved to /data/cmpe249-fa22/Mymodels/eval/nuscenes_models_cbgs_pp_multihead_0624/txtresults
Updated Evaluation (October 2023)¶
(mycondapy310) [010796032@cs001 3DDepth]$ python mydetector3d/tools/myevaluatev2_nuscenes.py --cfg_file='mydetector3d/tools/cfgs/nuscenes_models/cbgs_pp_multihead.yaml' --ckpt='/data/cmpe249-fa22/Mymodels/nuscenes_models/cbgs_pp_multihead/0522/ckpt/checkpoint_epoch_128.pth' --tag='1021' --outputpath='/data/cmpe249-fa22/Mymodels/' --gpuid=3
(mycondapy310) [010796032@cs001 3DDepth]$ python mydetector3d/tools/myevaluatev2_nuscenes.py --cfg_file='mydetector3d/tools/cfgs/nuscenes_models/bevfusion.yaml' --ckpt='/data/cmpe249-fa22/Mymodels/nuscenes_models/bevfusion/0522/ckpt/checkpoint_epoch_56.pth' --tag='1021' --outputpath='/data/cmpe249-fa22/Mymodels/' --gpuid=3
BEVFusion Architecture¶
Model Components¶
The BEVFusion model integrates camera and LiDAR data through a sophisticated multi-modal fusion architecture. The forward process includes the following major components:
1. MeanVFE (Voxel Feature Encoder)¶
Input:
voxel_features([600911, 10, 5]),voxel_num_points([600911])frombatch_dict['voxels'],batch_dict['voxel_num_points']Output:
batch_dict['voxel_features'] = points_mean.contiguous()[600911, 5]
2. VoxelResBackBone8x (3D Backbone)¶
Input:
voxel_features([600911, 5]),voxel_coords([600911, 4])frombatch_dict['voxel_features'],batch_dict['voxel_coords']Output:
batch_dict: 'encoded_spconv_tensor': out([2, 180, 180]),'encoded_spconv_tensor_stride': 8,'multi_scale_3d_features'
3. HeightCompression (BEV Mapping Module)¶
Input:
encoded_spconv_tensor = batch_dict['encoded_spconv_tensor'](Sparse[2, 180, 180])Output:
batch_dict['spatial_features'] = spatial_features[6, 256, 180, 180],batch_dict['spatial_features_stride']=8
4. SwinTransformer (Image Backbone)¶
Input:
x = batch_dict['camera_imgs'][6, 6, 3, 256, 704]Output:
batch_dict['image_features'] = outs(3 items:[36, 192, 32, 88],[36, 384, 16, 44],[36, 768, 8, 22])
5. GeneralizedLSSFPN (Feature Pyramid Network)¶
Input:
inputs = batch_dict['image_features']Output:
batch_dict['image_fpn'] = tuple(outs)(2 items:[36, 256, 32, 88],[36, 256, 16, 44])
6. DepthLSSTransform (View Transformation)¶
Lifts images into 3D and projects onto BEV features (from BEVFusion repository)
Input:
x = batch_dict['image_fpn'][6, 6, 256, 32, 88],points = batch_dict['points'][1456967, 6]Output:
batch_dict['spatial_features_img'] = x[6, 80, 180, 180]Components: dtransform, depthnet, downsample
7. ConvFuser (Multi-modal Fusion)¶
Input:
img_bev = batch_dict['spatial_features_img'][6, 80, 180, 180],lidar_bev = batch_dict['spatial_features'][6, 256, 180, 180]Process:
cat_bev = torch.cat([img_bev,lidar_bev],dim=1)Output:
batch_dict['spatial_features'] = mm_bev[6, 256, 180, 180]
8. BaseBEVBackbone (2D Backbone)¶
Input:
spatial_features = data_dict['spatial_features'][6, 256, 180, 180]Output:
data_dict['spatial_features_2d'] = x[6, 512, 180, 180]
9. TransFusionHead (Detection Head)¶
Loss Functions: SigmoidFocalClassificationLoss(), L1Loss(), GaussianFocalLoss()
Input:
feats = batch_dict['spatial_features_2d'][6, 512, 180, 180]Output:
res = self.predict(feats)containing:'center'[6, 2, 200]'height'[6, 1, 200]'dim'[6, 3, 200]'rot'[6, 2, 200]'vel'[6, 2, 200]'heatmap'[6, 10, 200]'query_heatmap_score'[6, 10, 200]'dense_heatmap'[6, 10, 180, 180]
Loss Computation:
loss, tb_dict = self.loss(gt_bboxes_3d [6, 51, 9], gt_labels_3d [6, 51], res)
Bird’s-Eye-View Conversion¶
LSS Model Implementation¶
A new folder (mydetector3d/datasets/nuscenes/lss) was added to test Bird’s-eye-view conversion based on the LSS model from lift-splat-shoot.
Installation Requirements¶
pip install nuscenes-devkit tensorboardX efficientnet_pytorch==0.7.0
Model Evaluation¶
The pretrained model is saved at /data/cmpe249-fa22/Mymodels/lss_model525000.pt. Using eval_model_iou from mydetector3d/datasets/nuscenes/lss/lssexplore.py for inference:
{'loss': 0.09620507466204373, 'iou': 0.35671476137624863}
Map Configuration Issue Resolution¶
When running viz_model_preds, an error occurred: “No such file or directory: ‘/data/cmpe249-fa22/nuScenes/nuScenesv1.0-mini/maps/maps/expansion/singapore-hollandvillage.json’”.
Solution:
(mycondapy39) [010796032@cs001 nuScenes]$ unzip nuScenes-map-expansion-v1.3.zip
Archive: nuScenes-map-expansion-v1.3.zip
creating: basemap/
inflating: basemap/boston-seaport.png
inflating: basemap/singapore-hollandvillage.png
inflating: basemap/singapore-queenstown.png
inflating: basemap/singapore-onenorth.png
creating: expansion/
inflating: expansion/boston-seaport.json
inflating: expansion/singapore-onenorth.json
inflating: expansion/singapore-queenstown.json
inflating: expansion/singapore-hollandvillage.json
creating: prediction/
inflating: prediction/prediction_scenes.json
(mycondapy39) [010796032@cs001 nuScenes]$ cp -r expansion/ nuScenesv1.0-mini/maps/
Visualization Results¶
After resolving the map issue, the evaluation figures from viz_model_preds show:
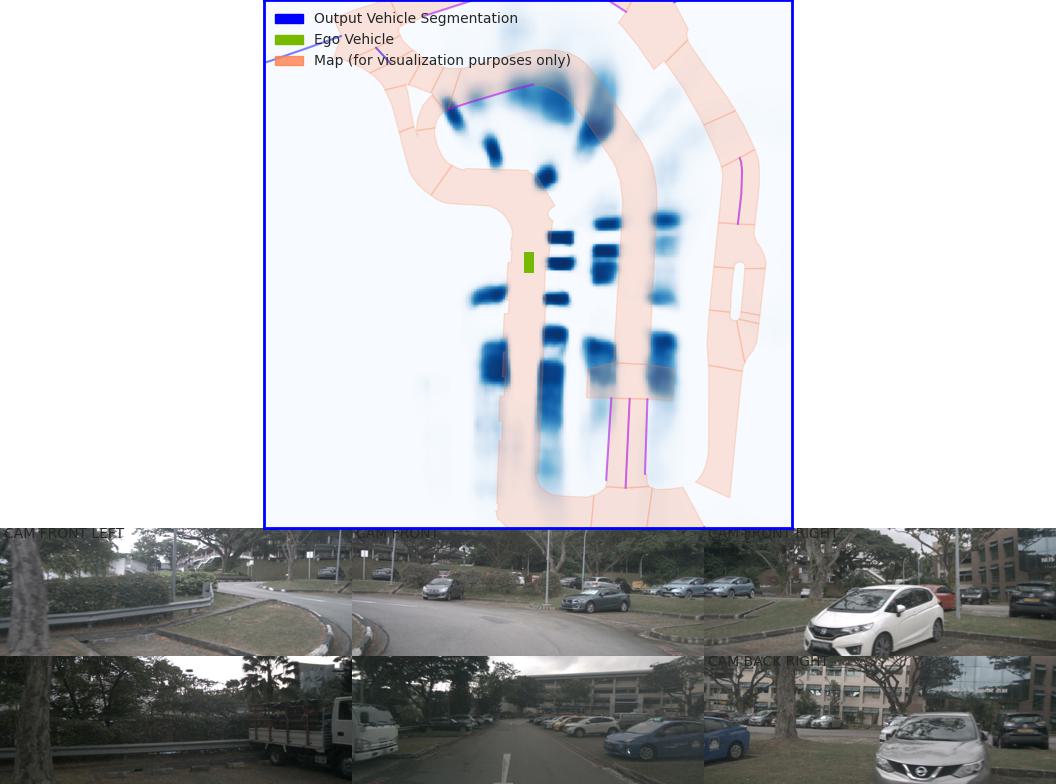
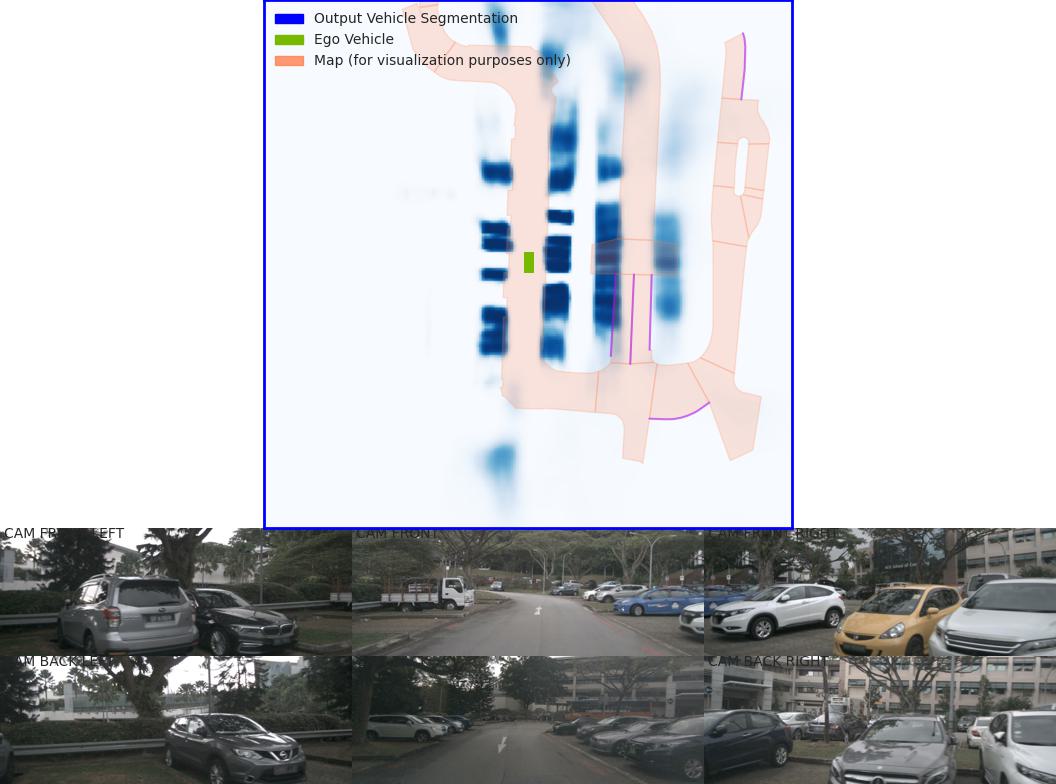
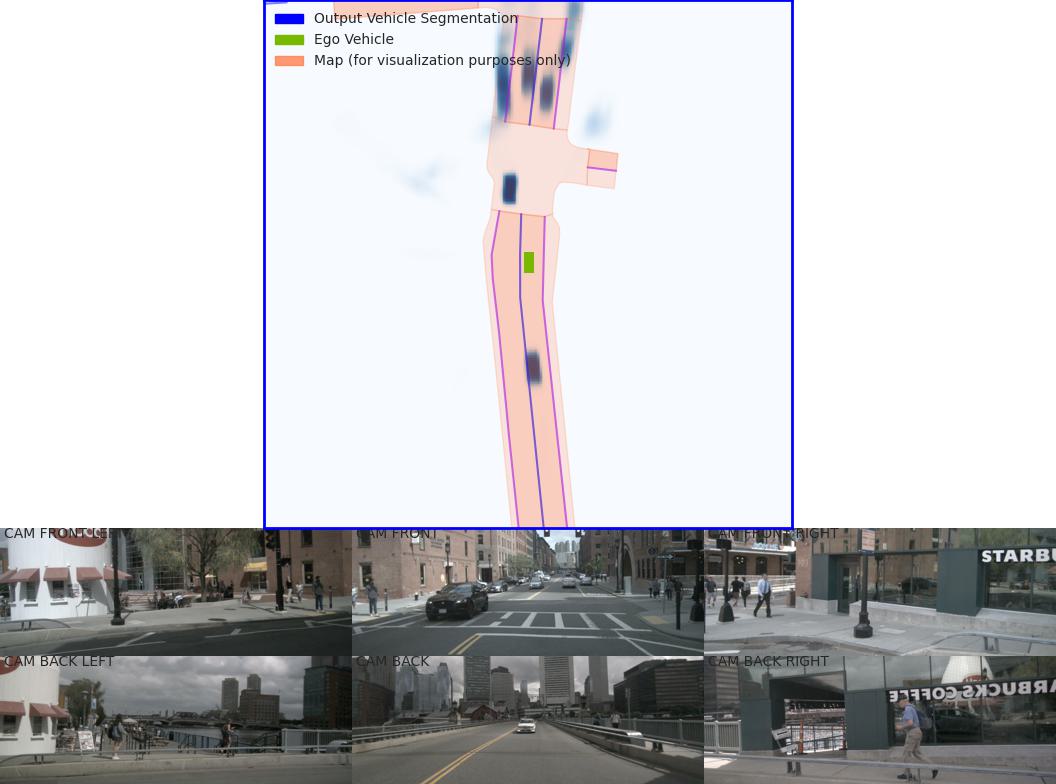
LiDAR Calibration Verification¶
The lidar_check function performs visual verification to ensure extrinsics/intrinsics are parsed correctly:
Left: Input images with LiDAR scans projected using extrinsics and intrinsics
Middle: The projected LiDAR scan
Right: X-Y projection of the point cloud generated by the lift-splat model


Training Results¶
Training was completed on /data/cmpe249-fa22/nuScenes/nuScenesv1.0-mini/ data using mydetector3d/datasets/nuscenes/lss/lssmain.py. The trained models are saved in the output folder: model1000.pt and model8000.pt. Using model8000.pt for inference:
{'loss': 0.23870943376311549, 'iou': 0.11804760577248166}